✅ User behaviours ✅ AI LLM technology ✅ User experience
LLM latency
Sophisticated general purpose LLM models like GPT-4 can take quite a while to fully respond to a prompt especially when the prompt or response is large.
Less sophisticated models can be faster, but their capabilities are generally weaker (or they are designed for specific applications) making them less suitable to many use cases.
This creates a challenging UX problem - users may be willing to wait for some amount of time but an experience that involves multiple LLM requests, with each one potentially taking as long as 30-90 seconds could be an issue.
Less sophisticated models can be faster, but their capabilities are generally weaker (or they are designed for specific applications) making them less suitable to many use cases.
This creates a challenging UX problem - users may be willing to wait for some amount of time but an experience that involves multiple LLM requests, with each one potentially taking as long as 30-90 seconds could be an issue.
09
Deep articles on LLM prompt engineering
Deep articles on LLM prompt engineering
03
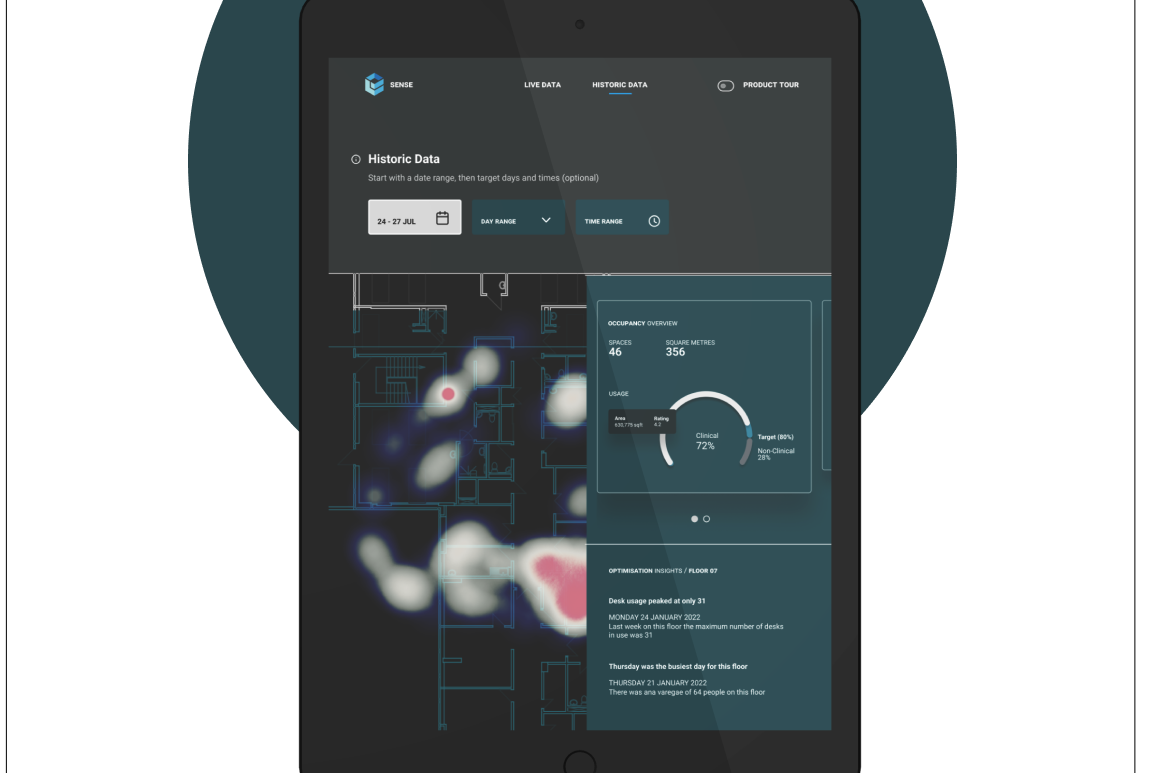
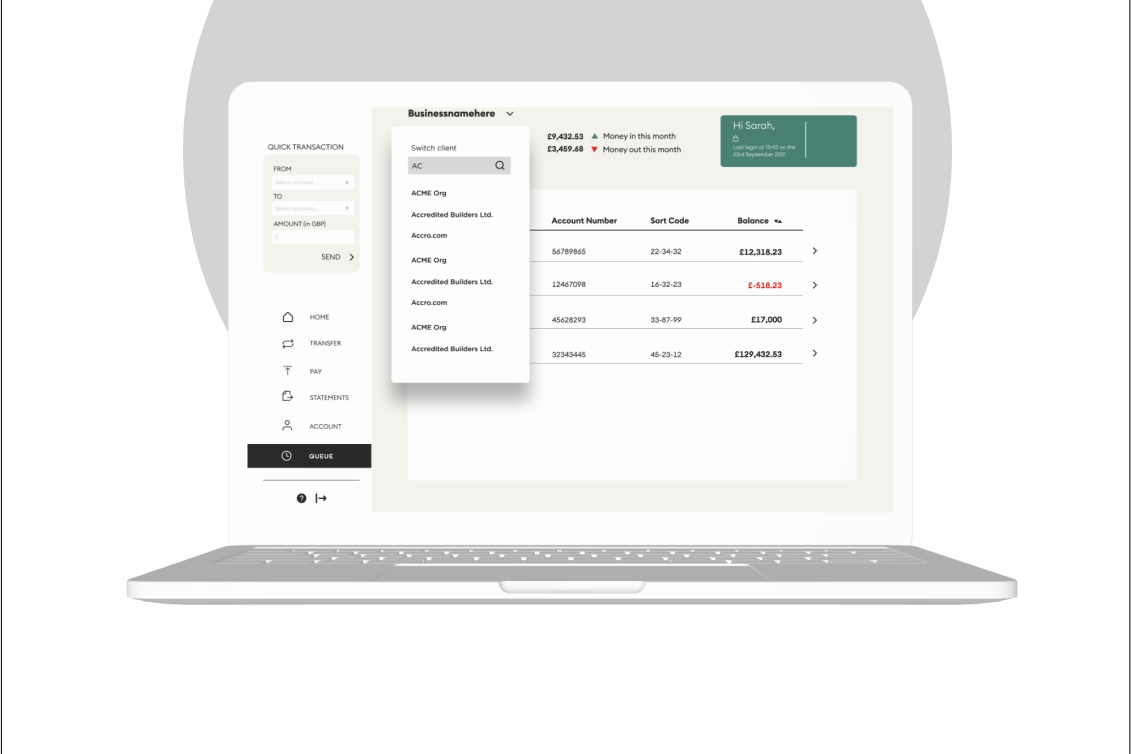
Analyses of existing LLM interfaces
Multi-shot prompting
This method builds on an LLM’s ability to learn and generalize information from a small amount of data. This is helpful when you don’t have enough data to fine-tune a model.
It means adding examples of the response type it giving the AI a tone, a reach and a format to work with. But users need to know about those parameters in the first place, to train the model for better outputs.
This method builds on an LLM’s ability to learn and generalize information from a small amount of data. This is helpful when you don’t have enough data to fine-tune a model.
It means adding examples of the response type it giving the AI a tone, a reach and a format to work with. But users need to know about those parameters in the first place, to train the model for better outputs.
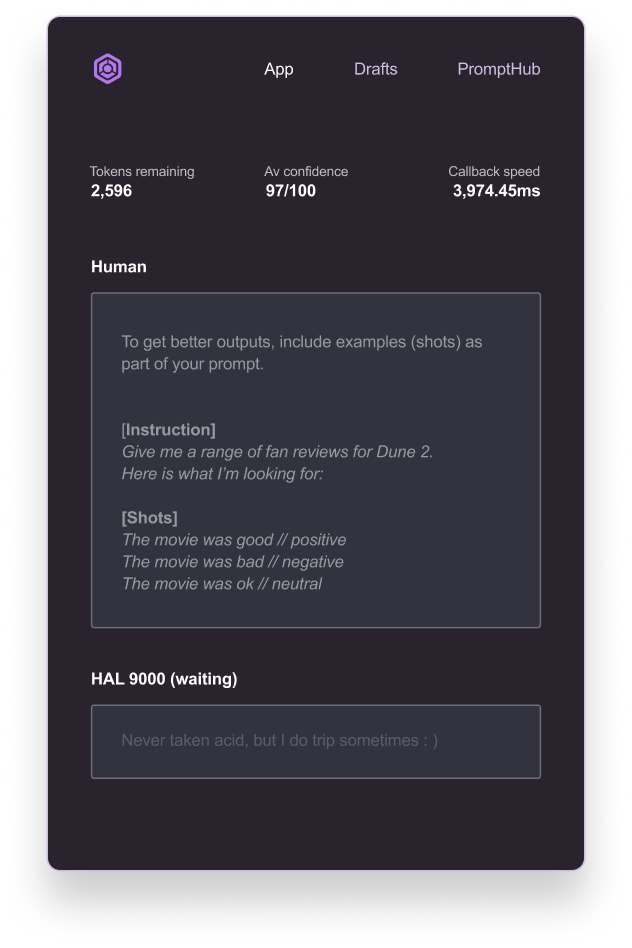
Part of LLM UX is to educate the users on how to reduce latency, not waste tokens and get better outputs
Rationale
This approach not only helps the model learn what we would deem as positive, negative, or neutral, but it also shows our desired output format is a single word, all lowercase.
There is also the risk of overfitting - where the model fails to generalize the examples and creates outputs that mimic the examples too closely.
There can be some biases to watch out for
There can be some biases to watch out for
Bias 01 / Majority Label
The model tends to favour answers that are more frequent in the prompt. If the prompt includes more positive than negative examples the model might be biased towards predicting a positive sentiment.
The model tends to favour answers that are more frequent in the prompt. If the prompt includes more positive than negative examples the model might be biased towards predicting a positive sentiment.
Bias 02 / Recency
LLMs are known to favour the last chunk of information they receive. If the last few examples in the prompt are negative the model may be more likely to predict a negative sentiment.
LLMs are known to favour the last chunk of information they receive. If the last few examples in the prompt are negative the model may be more likely to predict a negative sentiment.
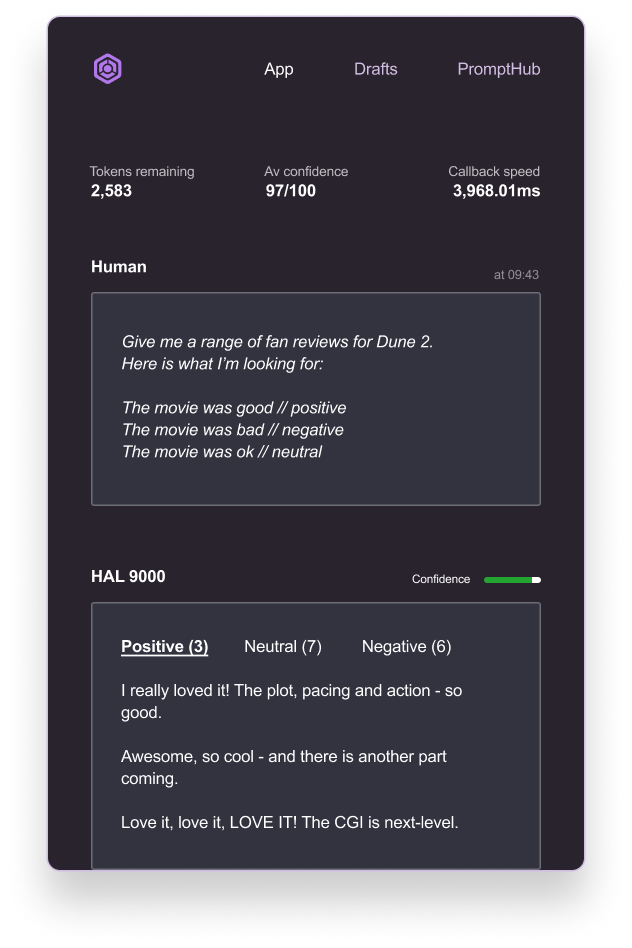
Confidence matters - show users how healthy the AI is behaving (or not)